6.2.2 音声符号化技術
音声信号の圧縮符号化では,主に次のような方法が利用されます.
- 信号に含まれている冗長な部分を除去する -- 信号の持つ相関に着目し,より少ない情報量で元の信号もしくはその近似値を表現します.元の信号値ではなく,予測の結果である予測誤差を用いる予測符号化や,統計的冗長度を除く可変長符号化が該当します.
- 人間の聴覚特性を利用する -- 聴覚の周波数特性やマスキング効果(雑音に対する感度は大きな信号に対して低下する)を考慮して,人間の耳には聞こえない所に符号化歪みを閉じ込めます.
- 音声生成機構のモデルを利用する -- 人の声は声帯,声道により発せられますので,その機構をなぞることで,音声波形そのままを処理するより効率よく人の声を表現できます.
この後,個々の符号化技術について詳しく説明します.
1) 非直線量子化
最初の電話音声符号化標準G.711[6-16]で用いられた符号化方法です.この標準は1972年の制定以来,現代でも電話網の中で広く使われていて最も長寿の標準です.適用されている技術は,第6.1節の図6-2で説明しましたA/D変換(PCM)です.ただし,電話音声信号の標本値は指数分布していて,零に近い値ほど頻度高く発生することに着目し,小さな標本値はきめ細かく,大きな標本値は粗く非直線量子化し,全体として量子化雑音を少なくします.
G.711ではμ則とA則という二つの非直線量子化特性を定義していて,μ則は北米,日本などで,A則は欧州,中国などで採用されています.国際電話では必要な場合両者の変換が行われます.
G.711μ則の具体的非直線特性を図6-11に示します.14ビット精度の入力標本値を8ビットの量子化代表値に対応づけています.量子化代表値は,入力が小さいときは密に定義され,入力が大きくなると粗に定義されていることがわかります.
余談ですが,この音声符号化方法が開発された当初は,アナログの音声信号をアナログの非直線回路で変換し,その結果を8ビット直線量子化する方法が行われていました.現代ではアナログの音声信号を14ビットでA/D変換し,その結果を定められた方法で8ビット符号に対応付けして非直線量子化を実現しています.
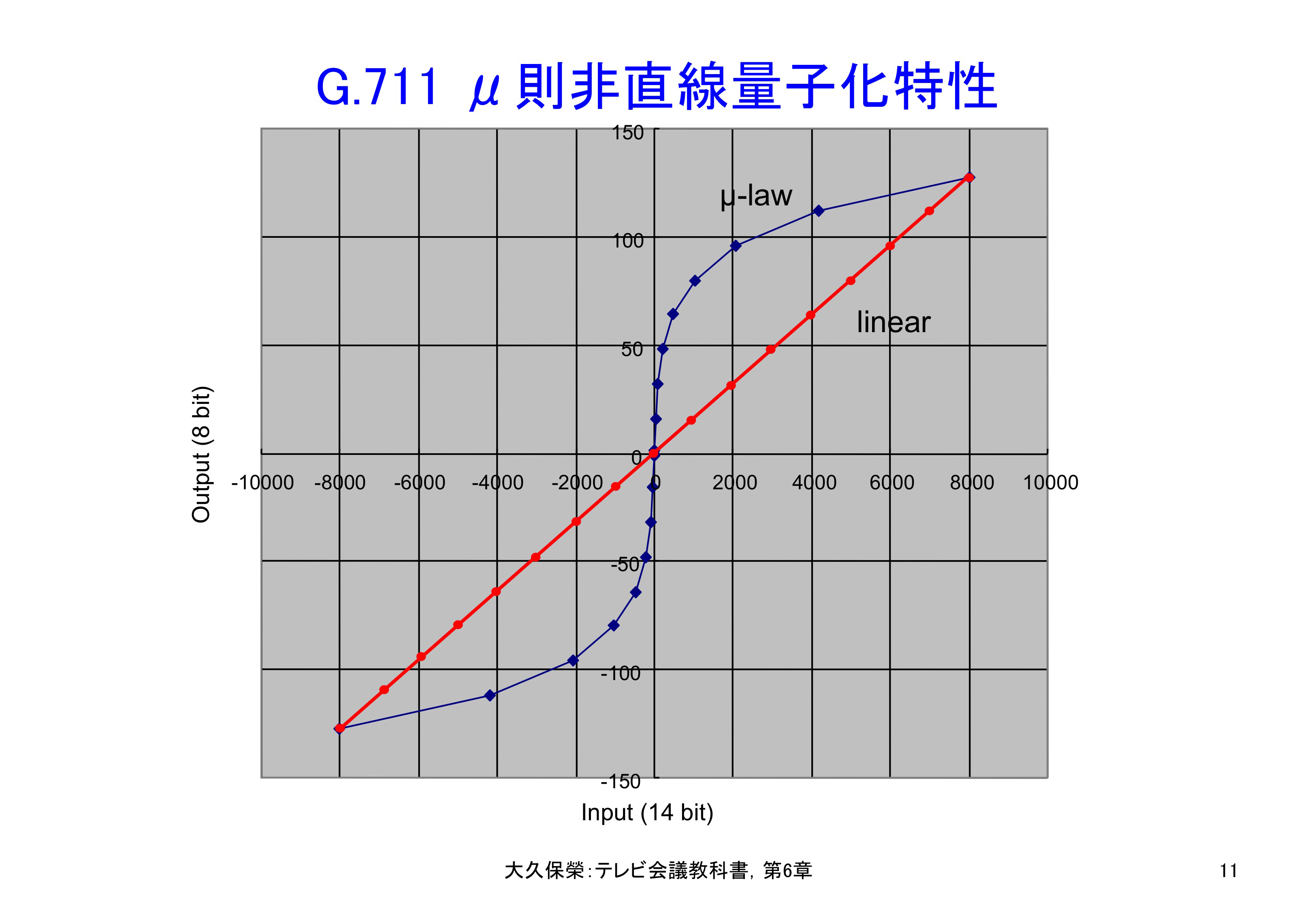
音声信号の標本値のレベル分布は零にピークを持つ指数分布で,小さな値ほど発生頻度が高くなります.音声信号全体の量子化誤差を最小にするには小さな信号は細かく量子化し(量子化雑音が小さい),大きな信号は粗く量子化する(量子化雑音は大きい)ことが有効です.この図はその非直線特性を示しています.実際の量子化出力は8ビット,すなわち量子化代表値は256個あります.
2) 予測符号化
自然界の事象には一般に継続性があります.今あるいは過去からの状態が分かれば将来どうなるか,ある程度予測できます.現在の標本値そのものではなく,過去の標本値から算出される予測値からの誤差を送るのが予測符号化の原理です.図6-12にその模様を示します[6-10].
音声信号は正弦波あるいは複数の正弦波が合成されたものとして近似されます.このような場合,予測がよく当たります.予測の係数が予測効率を決める鍵になりますが,一定区間の音声信号に対し予測誤差が最小になるように定めます.大きな音小さな音,高い音低い音,のように区間毎に音声信号の性質が変化しますので,それに合わせて予測係数を適応的に定めます.
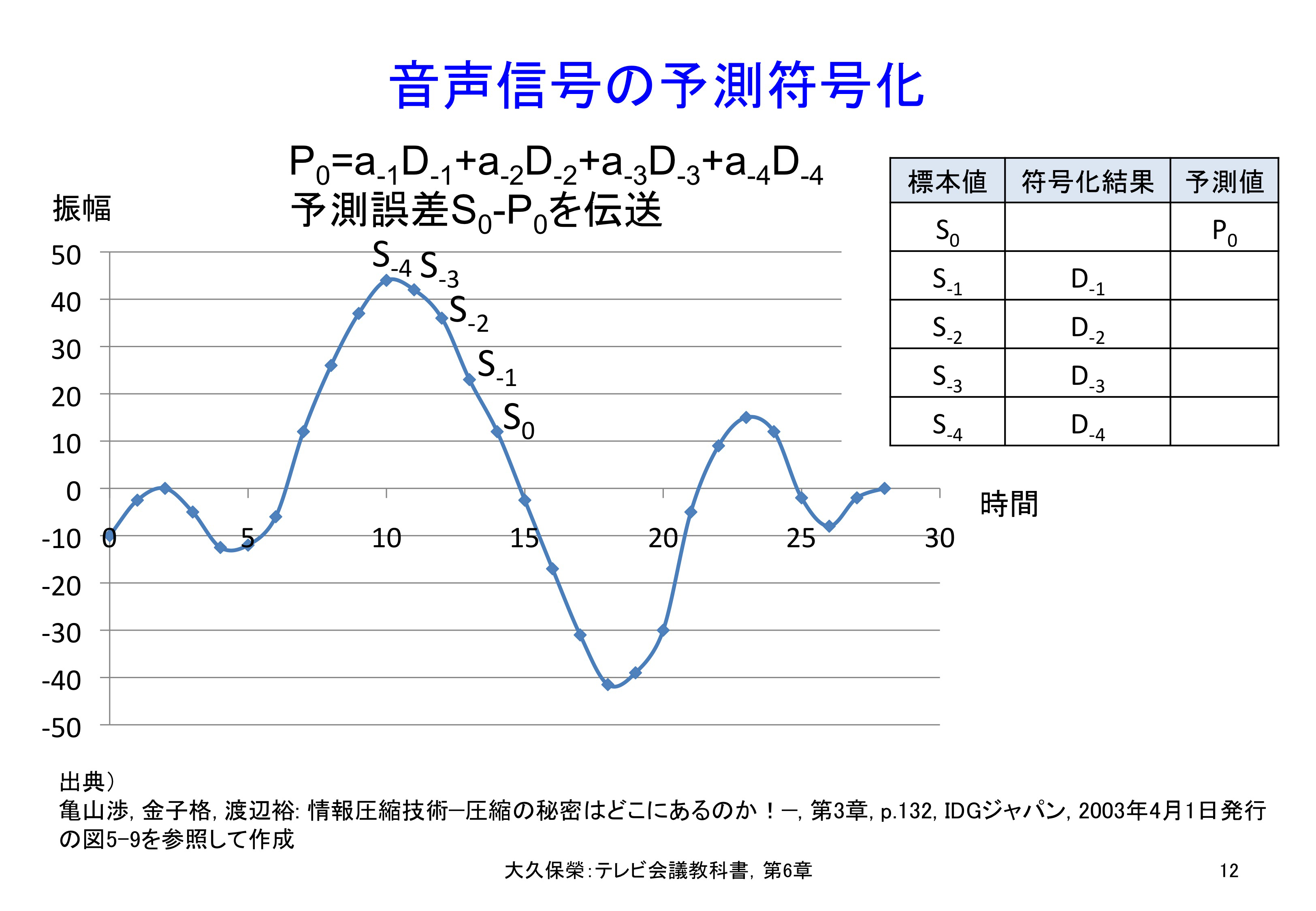
過去の符号化済み標本値(複数)の各々に重み付け係数を掛けて加えた値を予測値とし,符号化すべき標本の値との誤差を送ります.予測があたればこの誤差は小さくなり,送るべき情報量が減って帯域圧縮効果を実現できます.実際には,予測誤差が最小になるように係数値a-1, a-2, a-3, a-4を選びます.復号側では,復号済みの標本値に予測係数を掛けた予測値を作り,これに送られて来た予測誤差を加えて現在の標本に対する復号結果とします(図6-32参照).
3) サブバンド符号化
サブバンド符号化は,音声信号をフィルタ群(フィルタ・バンクと呼ばれる)で複数の周波数帯域に分け,各帯域に適した符号化処理を行うことにより,全体として効率よく圧縮符号化する方法です.フィルタ群で分けられた各帯域の信号は,耳の感度,雑音の感じ方の特性を考慮した精度で表現するなどの処理を受けます.
分割帯域の数は,G.722[6-17]のように2分割の例から,ISO/IEC 11172-3 MP3オーディオ(MPEG-1 Audio Layer 3)[6-18]のように32分割の例まであります.
4) 分析合成符号化
この符号化方法の基になっているのは,図6-13に示しますような人間の音声発生機構です.楽器と同じような構造です.声帯を震わせることで一定ピッチの音源とし,喉や口の形を変えることで声道の特性を変え,音源からの信号を変調して様々な音を発生する,という仕組みです.PCMによればこの世に存在するありとあらゆる音を表現できますが,人間の発する声は発生機構が定まったサブセットですから,PCMより効率よく表現できるはずです.
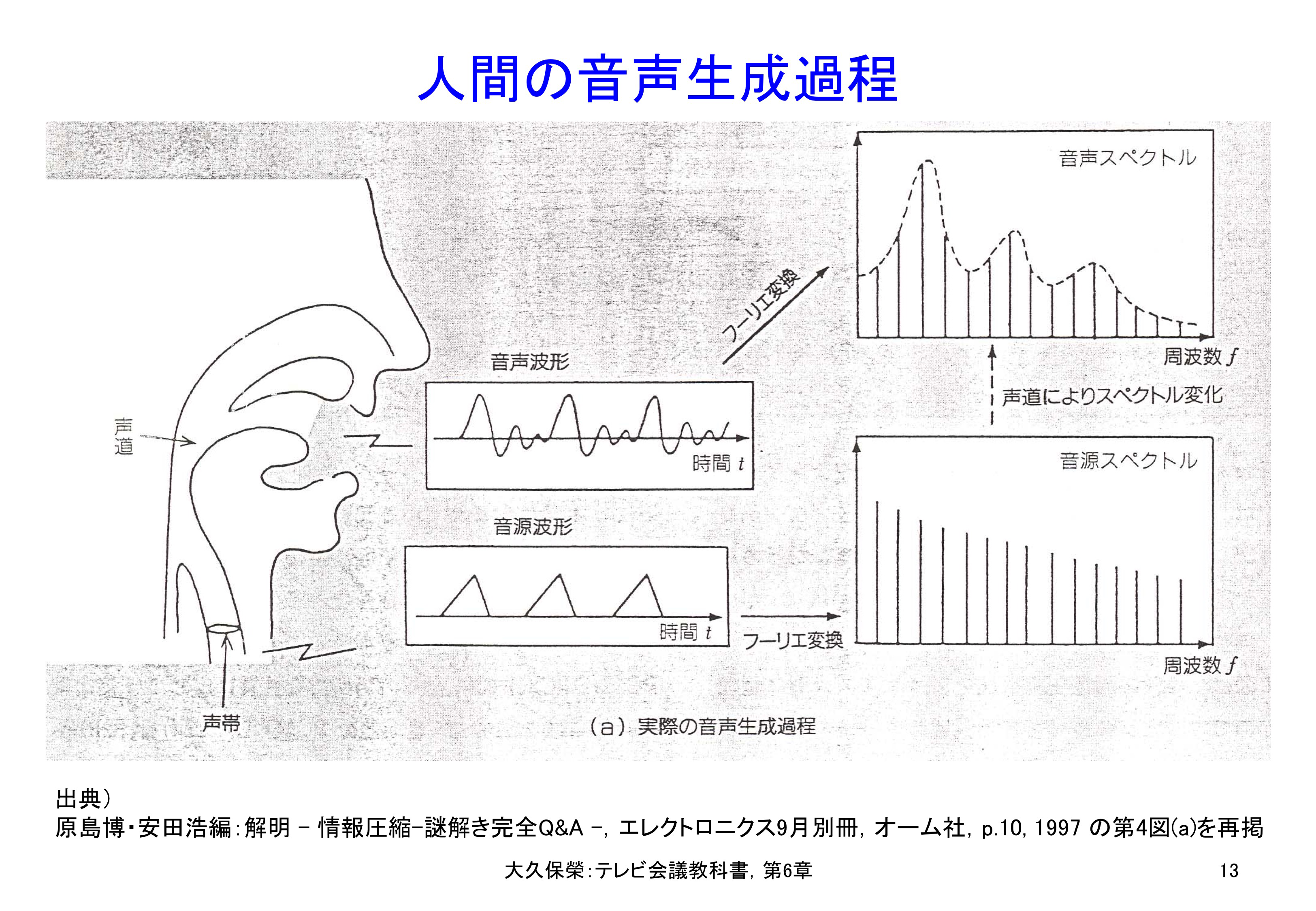
声帯が音源となり,ここからの音が声道を通る間に多様な音に変えられます.周波数領域では,音源波形は音源スペクトルとして,口から発せられる音声波形は音声スペクトルとして表現されます.
音声発生機構を電子回路で模擬して,少数のパラメータ値を送ることで帯域圧縮符号化するのが図6-14の分析合成符号化です.符号化すべき音声信号を分析して,音源を表すパラメータ(図6-14の音源情報),声道の伝達特性を表すパラメータ(図6-14のスペクトル包絡情報)を抽出し,元の音声信号の代わりに伝送します.受信側では,これらのパラメータを利用して人工的に作った音源,伝達特性から符号化入力の音声を合成して再現し,出力します.
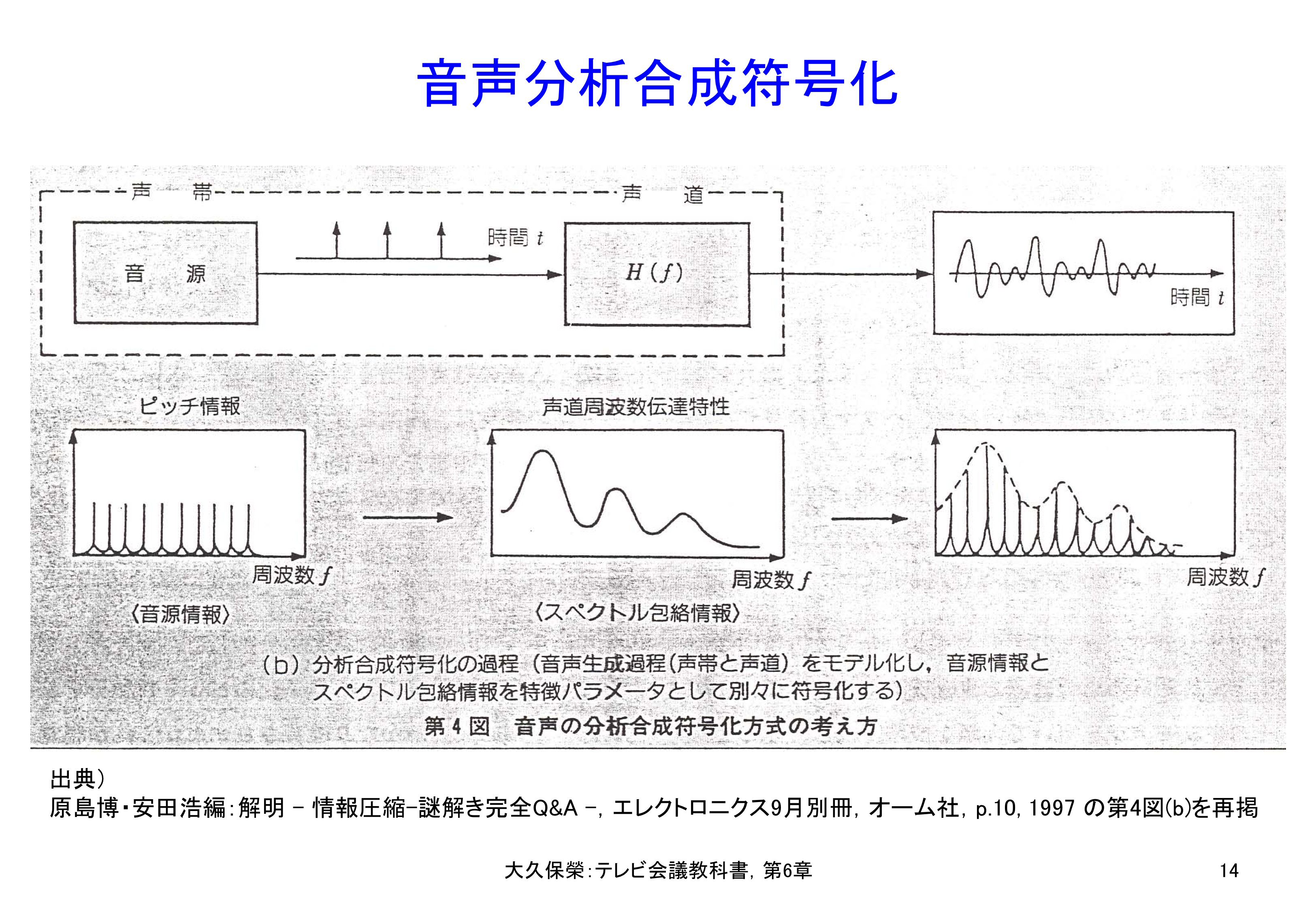
人間の音声生成機構に着目し,音源を表すパラメータと声道の伝達関数を表すパラメータを分析・抽出して送り,受信側ではそのパラメータから元の音声を合成する符号化方法です.
分析合成符号化の具体例にCELP(Code Excited Linear Prediction,符号励振線形予測,セルプと読む)符号化があります[6-19].その構成を図6-15に示します.入力音声信号を線形予測分析することでスペクトル包絡情報を抽出し,これにより音声合成フィルタを制御して声道の伝達特性を模擬します.音源の方は複数候補からなる励振コードブックを用意し,入力信号と音声合成フィルタ出力の誤差(すなわち符号化誤差)が最小になるように候補を選択します.その際,符号化誤差には聴覚重み付けフィルタを適用し,聞いたときの誤差が最小になるような音源コードを選択します.
CELP符号化技術は16 kbit/s以下の低ビットレート音声符号化で多用されています.CELP自体は共通的な技術名で具体的な符号化方式ではいろいろな変形が行われています.
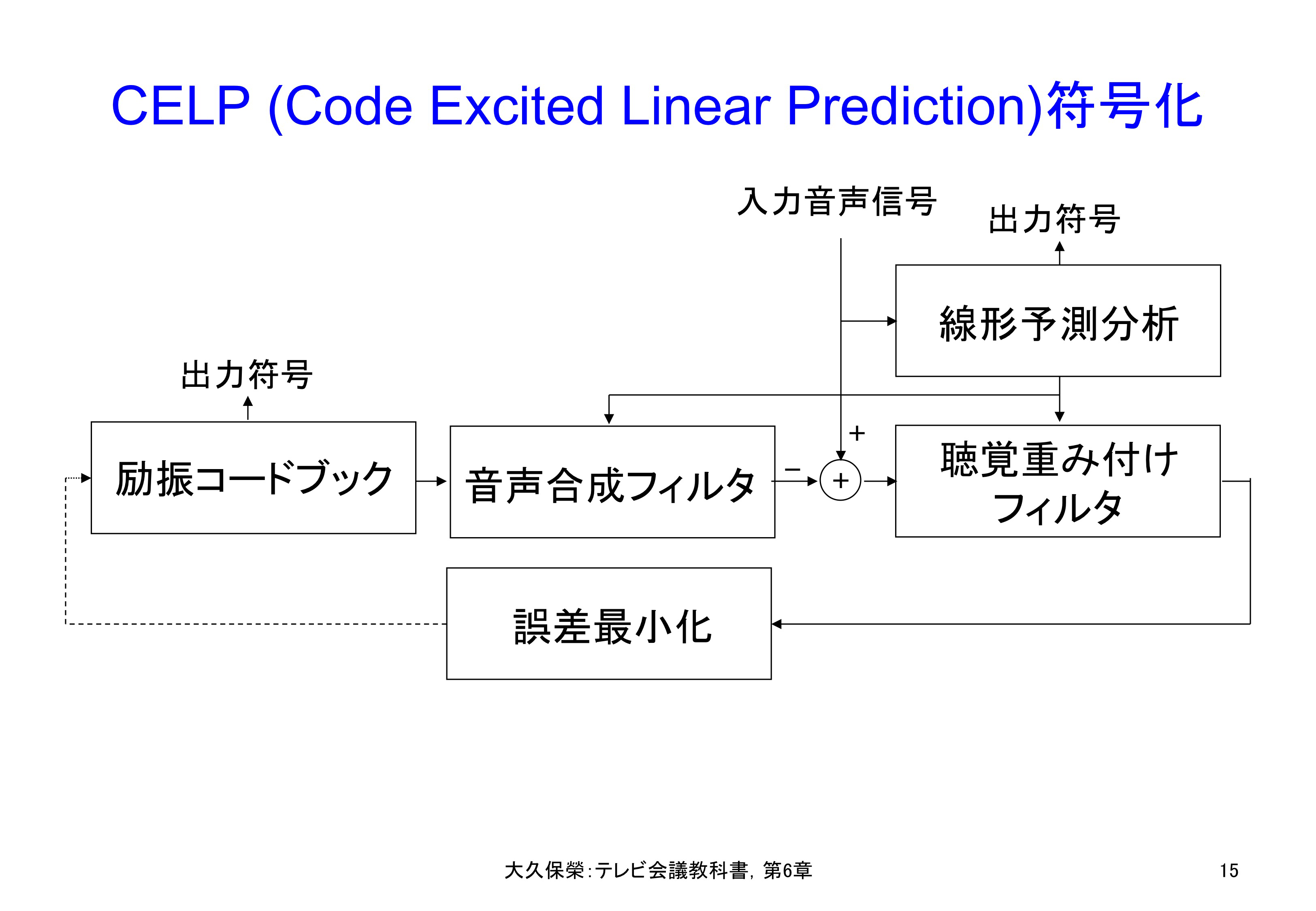
CELP符号化は,入力信号を線形予測分析して求めた予測係数を量子化し,量子化代表値に基づく線形予測合成フィルタを音源コードブックの出力で駆動します.音声合成フィルタの出力と入力信号の誤差が聴覚的に最小化されるように音源コードブックから最適候補を選びます.
5) ベクトル量子化
量子化は,第6.1節の2)で触れましたように,アナログ標本値をあらかじめ定めた離散的なディジタル値にマッピングする処理です.これを複数の標本値の組み合わせに対し,代表的な組み合わせの番号にマッピングするのがベクトル量子化です. CELPでは励振コードブックにこの技術が適用されています.励振コードブックの各々は一定区間の複数標本からなる波形を表していますので,よくある波形に短い符号を割り当てることで,効率的に符号化することができます.
6) 階層符号化
通常の符号化は,入力信号に対し1個の符号化ストリームを生成します.階層符号化では複数ストリームを生成し,伝送帯域幅に応じて送信側でストリーム数を制限する,あるいは全ストリームが送られたとしても受信側の処理能力に応じ,必要なストリームのみ受信します.勿論,利用ストリーム数に応じ再現品質は異なります.
一例として,G.722[6-17]を取り上げます.G.722は7 kHz帯域の広帯域音声信号を64 kbit/sで符号化する方式です.最初に入力信号を低域と高域の二つのサブバンドに分け,低域信号は48 kbit/sで高域信号は16 kbit/sで符号化します.このとき,低域信号は6ビットで表現しますが,そのうち4ビットが核となり,それを利用すれば7 kHz帯域音声信号を48 kbit/sで,追加の1ビットを利用すれば56 kbit/sで,追加の2ビットを利用すれば64 kbit/sで符号化されます.利用追加ビットに応じ品質がよくなります.
このように核となるストリームに高品質化のためのストリームを加える方法は,embedded(埋め込み)形の符号化と呼びます.