6.1 共通技術
1) メディア符号化の構成要素
この節では,音声符号化,映像符号化に共通する技術を説明します.メディア符号化の枠組みを図6-1に示します.
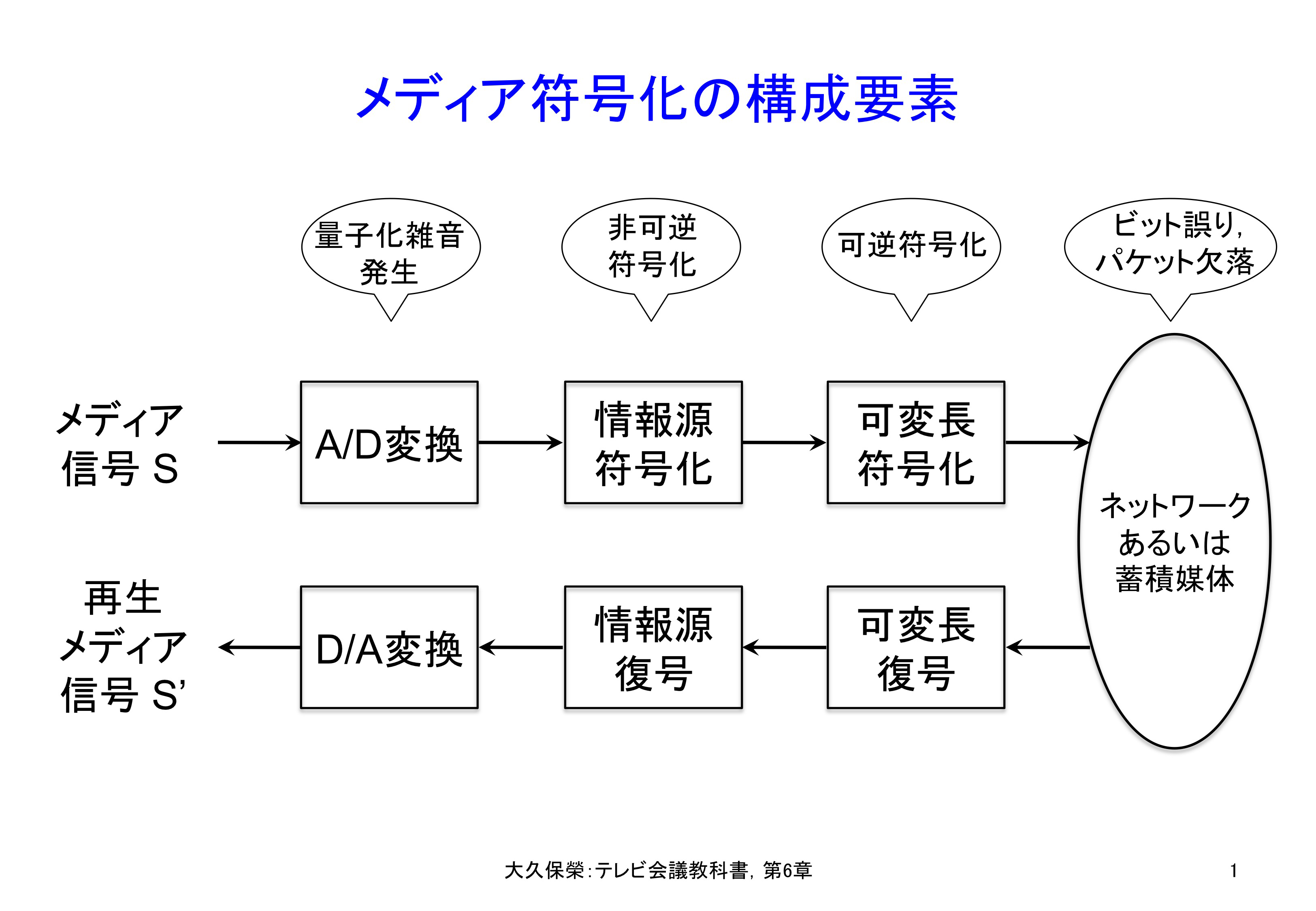
アナログの音声あるいは映像信号が入力されると,まずA/D変換により時間的にも振幅的にも離散的なディジタル信号となります.この処理は量子化雑音が発生するため厳密には非可逆の処理ですが,事実上は可逆処理と見なせます.次にこれを情報源符号化処理により音声信号あるいは映像信号に含まれる冗長部分を除去して若干の符号化歪み・雑音を許容することで大幅に圧縮します.これは処理の性質上,非可逆符号化です.最後に発生した符号語の統計的冗長度を除去するための可変長符号化が行われます.これは元の符号に完全に戻せる処理ですので可逆符号化です.
マイクロホンからの音声信号,カメラからの映像信号はアナログ信号Sとして符号器に入力されます.帯域圧縮符号化を含めた信号処理が可能なように,アナログ情報源信号SはA/D(Analog to Digital)変換によりディジタル化されます.逆の過程はD/A(Digital to Analog)変換です.A/D変換後の信号をD/A変換しますと,元の信号に極めて近い信号が得られます.わずかな誤差は量子化雑音と呼ばれ,変換の精度を高めれば,実用上無視できる程度に抑えることができます.
A/D変換に続く情報源符号化処理は,メディア信号に含まれる冗長度を除去する処理です.情報源復号,D/A変換後に得られる信号をS'とすると,人間の感覚で捉えられないような,あるいは捉え難い歪みや雑音δ(= S' - S)を許容することで大幅な帯域圧縮を実現します.同じ種類の符号化歪み・雑音であれば物理量としてのδが大きいほど主観的な感じ方も強くなりますが,符号化歪み・雑音の種類が異なると感じ方も変わってくることに注意が必要です.
情報源符号化結果はディジタルの符号語として表現されます.各符号語には発生頻度の高低があり,統計的な性質を利用してより少ないビット数に変換する可変長符号化を適用します.この処理は情報理論的な圧縮処理ですので,新たな符号化歪みや雑音を生じることはありません.
可変長符号化処理結果は多重化やパケット化の処理(図6-1では省略)の後ネットワークに送られたり,蓄積媒体に記録されます.ネットワークや蓄積媒体は完全ではなく,パケット損失やビット誤りにより若干の情報が欠落する場合があります.復号側では必要に応じこれを訂正したり隠蔽(conceal)したりします.
ここで,符号化による歪みや雑音δが零の処理は,復号後に符号化前の情報が完全に復元できることから可逆符号化と呼びます.可変長符号化がその例です.一方δが非零の処理は,復号しても符号化前の情報を完全には復元できないことから非可逆符号化と呼びます.情報源符号化がその例です.
2) A/D変換
A/D変換処理を図6-2に示します[6-1].この図は電話音声を例にしていますが,映像の場合もパラメータの値が変わるだけで原理は同じです.A/D変換処理はPCM (Pulse Code Modulation,パルス符号変調)[6-2]とも呼ばれます.
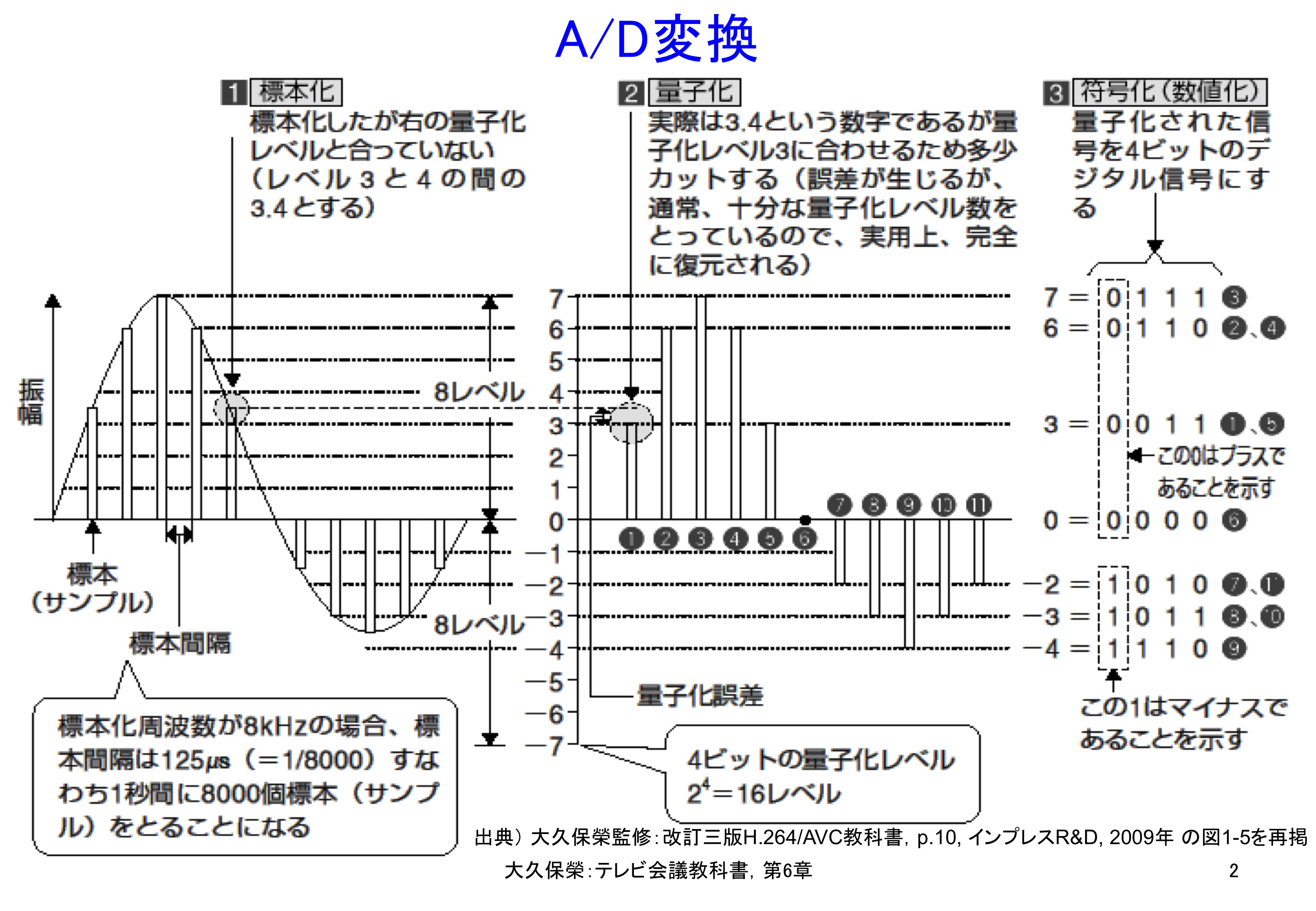
入力アナログ信号を標本化,量子化の後,その結果をディジタル符号語で表現します.D/A変換では,受信したディジタル符号語を量子化代表値に変え,さらにこれをフィルタ処理することで元のアナログ信号を再現します.
入力アナログ信号は,まず,その帯域幅の2倍以上の周波数で標本化され,時間方向に離散的な値として表現されます.これが理論的に元のアナログ信号に戻せることは,シャノン(Shannon)・染谷の標本化定理あるいはナイキスト(Nyquist)の定理として知られています[6-3].Nyquist氏が1928年に予測し[6-4],Shannon氏が1949年1月に証明を出版[6-5],それとは独立した研究により染谷氏が1949年10月に証明を出版しました[6-6].
A/D変換ではアナログ標本値があらかじめ定めた離散的なディジタル値にマッピングされます.この過程を量子化(quantization)と呼びます.図6-2の例では量子化の代表値は整数で,❶の実際の標本値は3.4ですが,小数点以下を丸めて3と表現されます.元の値より0.4だけずれていますので,これが量子化雑音となります.もし信号の振れ幅がこれに比べて十分大きければ量子化雑音の影響は無視できます.例えば8ビット量子化では信号の振れ幅は255ですので,それに対し+/- 0.5の量子化誤差は十分小さいと言えます.
A/D変換最後の処理は,離散的な量子化結果を符号語で表現することです.図6-2の例では4ビットの符号語ですが,実用的にはより高い量子化精度が適用され8〜16ビットの符号語で表されます.
3) 情報源符号化
メディア情報の圧縮率を決める核となる処理です.処理結果を逆にたどっても符号化歪みや雑音のため元の情報には戻せません.すなわち情報源符号化は非可逆符号化処理です.具体的な圧縮方法は,音声については第6.2.2項で,映像については第6.3.2項で紹介します.
注)ここでは勧告ITU-T H.261[6-7]に従い,非可逆の「情報源符号化(source coding)」を可逆符号化である可変長符号化に対峙する用語として用いています.メディア符号化に関する書籍では「情報源符号化」を雑音などが存在する場合に効率よく符号を送る技術である「伝送路符号化(channel coding)」に対峙する用語として用いている例[6-8]もあります.文脈に応じ「情報源符号化」がどちらの意味で使われているか注意が必要です.
4) 可変長符号化
可変長符号化により処理した結果は,符号量は減っているにもかかわらず完全に元に戻すことができますので,可逆符号化です.音声符号化,映像符号化に共通する技術ですので,ここで詳しく見てゆきます.
情報源符号化の結果は,例えば音声信号の振幅値であったり,映像符号化で出てくる動きベクトル値であったりします.これらは有限個の選択肢の一つとして表現されますので,言わば文章におけるアルファベットの一文字に相当します.可変長符号化の原理は,モールス符号と同様,頻度の高い符号語(アルファベット文字)は短い符号で表現し,頻度の低い符号語は長い符号で表現することにより,メッセージ全体として符号量を減らす働きをします.すなわち圧縮が行われ,モールス符号の場合ではメッセージの伝達時間を短くする効果があります.
図6-3に実際のモールス符号を,図6-4に英文アルファベットの出現頻度を示します.英文では"e"の出現頻度は群を抜いていて,最短の符号が割り振られています.図6-4は暗号解読をテーマにした書籍から引用していますが,最も初歩的な暗号は元の文字を別の文字で置き換える方法で,その場合英文であれば暗号文で最も出現頻度の高い文字を探しそれを"e"とすることから解読が始まります.

英文のモールス符号は短点と長点の組み合わせで表現されます.アルファベット文字の出現確率を考慮してよく現れる文字(例えば"e"や"t")は最短符号で,滅多に現れない文字(例えば"q"や"z")は長い符号で表現されます.こうすることにより英文メッセージ全体がより短時間に送れます.
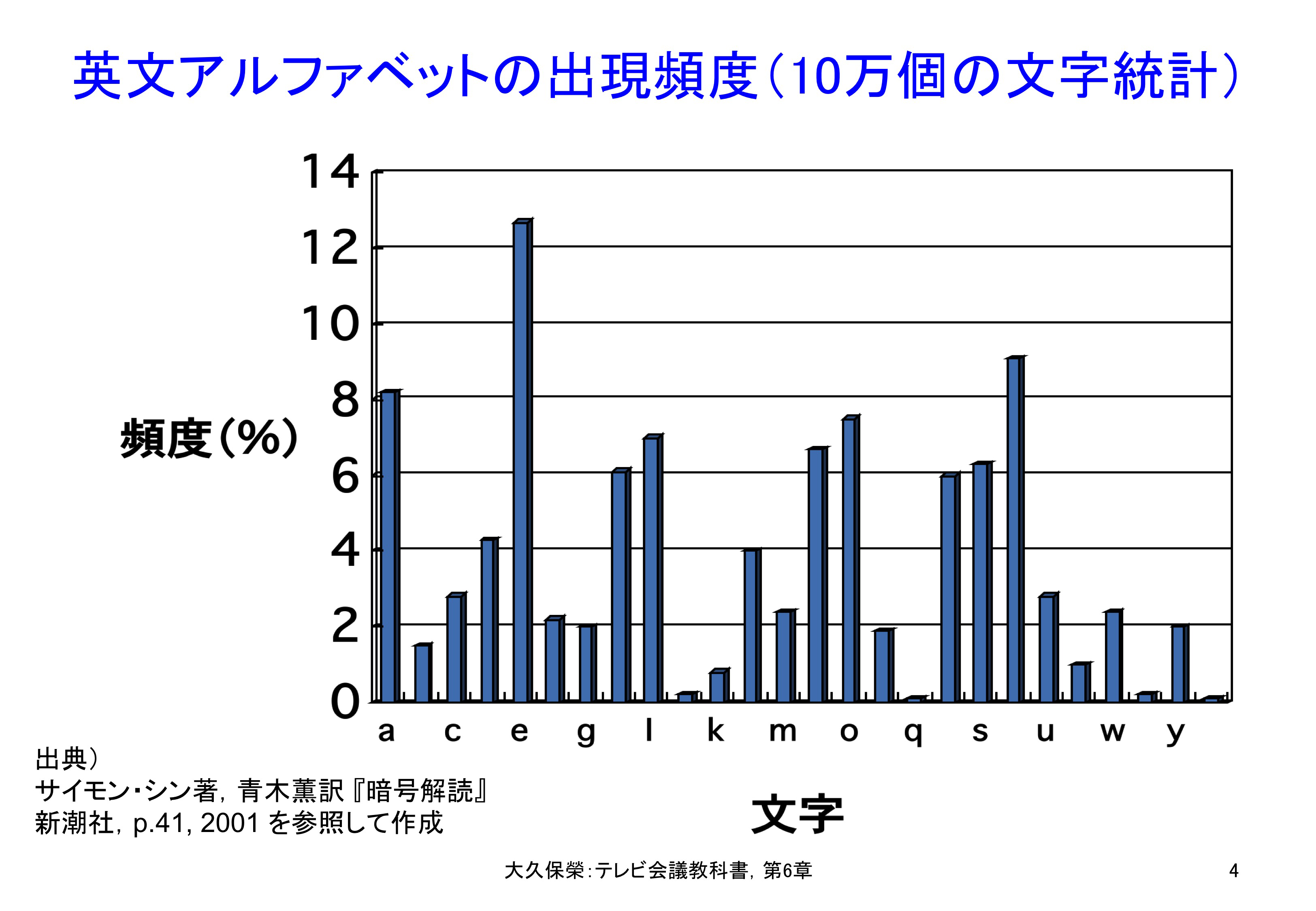
10万個の文字統計から,アルファベット各文字の出現頻度を示しています."e"や"t"は頻繁に現れ,"q"や"z"は余り出現しません.この統計がモールス符号設計あるいは英文に対するハフマン符号設計の基になります.
アルファベット(有限な数の事象を表す広い意味でこう呼んでいます)の出現頻度が与えられたとき,最も効率の高い可変長符号を設計する方法はハフマン符号化(考案者のDavid Albert Huffmanに因む)として知られています[6-9].
符号設計の具体例を図6-5に示します[6-10].アルファベット8個の事象を符号化しようとしていますので固定長符号化であれば3ビットで表現できます.ハフマン符号化を行うと平均して2.38ビットで表現でき,固定長符号化に比べ符号量は2割減となります.
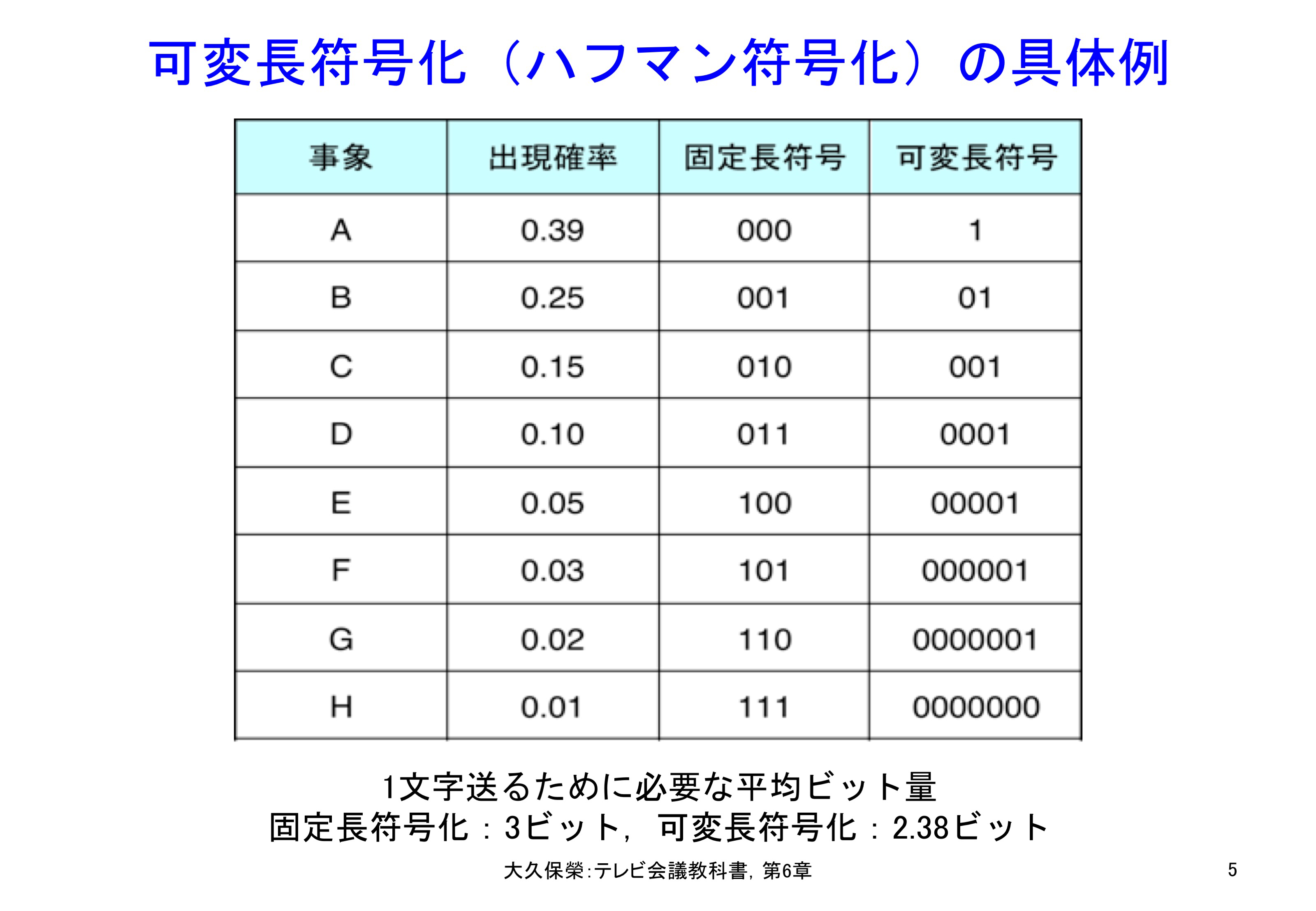
8個のアルファベットからなる事象について各アルファベットの出現頻度とハフマン符号の割り当て例です.固定長符号化では1アルファベットあたり3ビットを必要としますが,ハフマン符号化では事象全体で平均して1アルファベットあたり2.38ビットで表現できます.20%の冗長度削減ができています.
ハフマン符号化の問題は,符号化対象のアルファベットにどんなに高い出現頻度の文字があっても1ビットでしか表現できないことです.このような場合,その文字種に加え連続個数を符号化する連長(ランレングス,run-length)符号化を組み合わせることにより,結果的に1ビットより少ない符号量でその文字を表現できます.H.261などで採用されている技術です.またファクシミリ情報の符号化では,各画素値は白("1")か黒("0")ですので,効率的符号化のために連長符号化が用いられています.
ハフマン符号化のもう一つの問題は,符号表を作る際,アルファベットの出現頻度を想定して設計することです.同じ英語の文章と言っても,コラム6-1で例示しますように,平均的には出現頻度が低く長い符号が割り当てられる"z"がやたらと出てくる文章や,逆に頻度が高く短い符号が割り振られる"e"が全く登場しない小説も存在します.このような文章をモールス符号で送ろうとすれば時間がかかってしまうことになります.
送るべきアルファベットの出現頻度にダイナミックに対応し符号を作成するのが算術符号化の技術です.算術符号化によれば,その文章が持つ理論的情報量に近い符号量で表現することができます.算術符号化は,多くの情報処理を必要としますので,近年プロセッサが強力になって実用的となった技術です.
算術符号化の原理は次の通りです[6-11].
いまM個の事象からなる符号化対象事象のm番目の発生確率がPmである場合,この符号化対象事象のエントロピーはPm log2(1/Pm)をm=0からm=M-1まで足し合わせた値になります.例えばAとBからなる事象では,その発生確率が両方とも1/2であれば1ビットのエントロピーですが,Aが1/8,Bが7/8の発生確率であればエントロピーは0.54ビットとなります.
そこで,算術符号化では,直線上の0から1までの区間を符号化対象事象の発生確率に応じて区間分けし,その区間を表現する最短の2進数を求めれば,可変長符号化結果となります.映像符号化で用いられる算術符号化では,符号器の入力を2進の符号列とし,符号が入力される都度この区間分けを細かくして出力符号を生成する過程を繰り返します(0から1までの数直線上の値は小数で表され,これを2進数表現すると小数部分の0/1符号列が符号化結果となります).
復号側では,受信した算術符号化結果から,上記区間分けの情報,すなわち0/1の発生確率情報を符号器/復号器間で共有することにより,符号器の入力信号を再現することができます.
5) メディア復号処理
復号側は符号化と逆に,受信した可変長符号を固定長符号に戻し,情報源復号によりPCM信号を取り出します.さらにこれをD/A変換することで,元のアナログ信号S'を再生します.この再生信号S'には符号化処理の際発生した歪み・雑音δが含まれていますが,たとえδが零でなくても,人間が聞いたり見たりしたとき支障のない程度であればよい,という工学的アプローチで帯域圧縮符号化を達成します.