5.4 音声と映像の相互作用に関わる人間要因
テレビ会議は音声と映像を同時に用いるマルチメディア通信です.これまで,音声,映像それぞれに関わる人間要因を説明してきましたが,ここでは音声と映像が同時に提示されることによる相互作用を三つ紹介します.
1) リンプシンク誤差
最初は音声と映像の遅延差(リップシンク,lip sync)を取り上げます.ディジタル時代に入り,音声,映像とも圧縮符号化のほか画面合成など多様な信号処理を受け,かつ放送では異なる伝送経路を通ることが加わって,利用者に提示するときには時間差を生じます.この時間差が大きくなると,人の話す声と画面上の口の動きが同期しなくなり,不自然な印象を与えます.後述しますが,ディスプレイの位置とスピーカの位置は少々離れていても画面上の人が話しているように感じられるのですが,リップシンクずれがひどくなると,声はスピーカの置かれた場所から出ていると物理的には正しい位置関係で認識されるようになります.
それでは,どれだけのリップシンク誤差が許されるのでしょうか.この場合も第5.3節 1)で述べましたように,人間の感覚には誤差はゼロでなくても支障のない範囲があります.NHKで行われた実験結果を図5-27に示します[5-32].
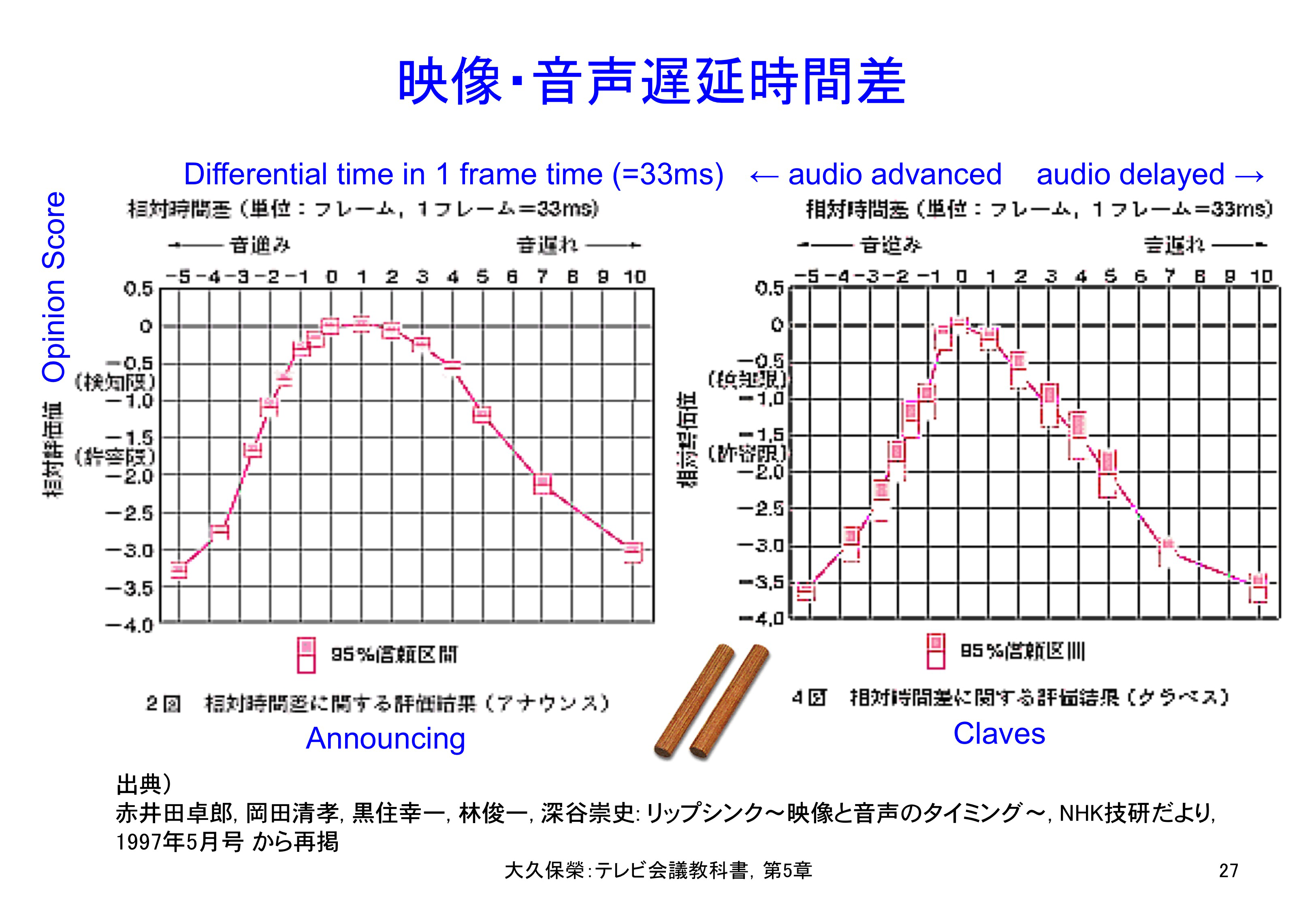
アナウンサーが話しかける場合と打楽器クラベスを叩く場合について,音声と映像の遅延差(リップシンク誤差)を主観評価した結果です.横軸の0が完全にリップシンクが取れている場合を示します.音声が映像に先行する場合は,遅れる場合に比べ,より妨害が感じやすくなっています.ここで「95%信頼区間」は,評価者によって評価結果にばらつきがあって,統計的に100回の実験のうち95回はこの区間に平均値が収まることを意味します.
左はアナウンサーが話している場面についての結果で,音声が映像より遅れている場合は5.6フレーム時間(186 ms,1フレーム時間=1/30 s=33.3 ms)まで,音声が映像より進んでいる場合は2.4フレーム時間(80 ms)までが許容範囲です.検知限では,前者が4フレーム時間(133 ms),後者が1.3フレーム時間(43 ms)と読み取れます.
図5-27右はクラベスという打楽器を打った場合の実験結果です.これは人が話す場合よりは厳しく,音声が映像より遅れている場合は4フレーム時間(142 ms)まで,音声が映像より進んでいる場合は1.7フレーム時間(57 ms)までが許容範囲です.検知限では,前者が1.8フレーム時間(60 ms),後者が0.8フレーム時間(27 ms)と読み取れます.
いずれの場合も非対称になっているのが注目されます.自然界では,音より光の方が先に届くので,画像より先に音が聞こえてくることは経験のない事態であることに起因していると思われます.因みに,自然の状態でも,人が遠くで話していればリップシンク誤差が生じるのですが,10 m離れていても,音が進むに要する時間は30 ms(約1フレーム時間)ですので,気づくことはありません.もっと遠くで話せば見えるようなリップシンク誤差があるかもしれませんが,今度は口の動きを識別することができなくなってしまいます.ディジタル信号処理では音声に比べ映像の処理により大きな遅延を生じますので,体感的にはリップシンク誤差がより厳しい方向です.
ここで引用したNHKのデータが基になって,勧告ITU-R BT.1359が作られました[5-33].そこでは許容限/検知限は音声が遅れる場合は185/125 ms,進む場合は90/45 msと図示されていて,番組が視聴者に届いたとき許容限を越える誤差があってはならないと規定しています.
このBT.1359規定は,NHKの実験結果でもクラベスの場合は厳しくなっていますように,放送の標準としては甘めと見なされています.実際,EBU (European Broadcasting Union, 欧州放送連合)の標準R37[5-34]では図5-28のように規定しています.音声と映像の同期ずれが生じる過程ごとに許される誤差は,音が遅れる場合は15 msまで,進む場合は5 msまでとして,システム全体で累積しても60 msまで,40 msまでとしています.

テレビ会議システム標準では,リップシンク誤差を規定したものはありませんが,テレプレゼンス・システムではITU-T G.1091[5-35]が上記EBU規定と同じシステム全体値を推奨しています
ここでテレビ会議システムにおいてリップシンクが果たす役割に触れます.次節(第5.5節)で議論しますが,テレビ会議の映像メディアが伝えているのは現実感,臨場感です.リップシンクが失われると,画面に現れている人と話しているという雰囲気やリアルさが失われてしまいます.
このような視点でメッセージ伝達に及ぼすリップシンクの影響を評価した実験結果を図5-29に示します[5-36].刺激はリップシンク誤差なしのSYNC,音声が2.5フィールド時間(42 ms)先行するMED. ASYNC,5フィールド時間(83 ms)先行するHIGH ASYNC,の3レベルです.評価対象は,商品紹介,ニュース,コマーシャル,政治家の演説,ニュース解説をテーマとする6ビデオ番組が用いられました.実験参加者は,いくつかの反対語対(例えばBadとGood,IneffectiveとEffective)の間に1から8までの数字を配置した尺度に,該当する印象をマークします.図5-29はBad - Goodの印象について,左は全てのビデオ番組を平均した評点で,2.5フィールド時間のずれでは若干評価が下がり,5フィールド時間のずれでは明らかに評価が下がっています.NHKの実験結果およびBT.1359では2.5フィールド時間のずれは検知限に,5フィールド時間のずれは許容源に相当します.図5-29の右は各ビデオ番組に対する評価結果です.この実験では,番組に登場する人物への印象も尋ねていて,リップシンク誤差5フィールドでは統計的に有意な差でよりネガティブ(面白くない,不愉快な,影響力がない,かき乱された,不成功な)に受け取られています.
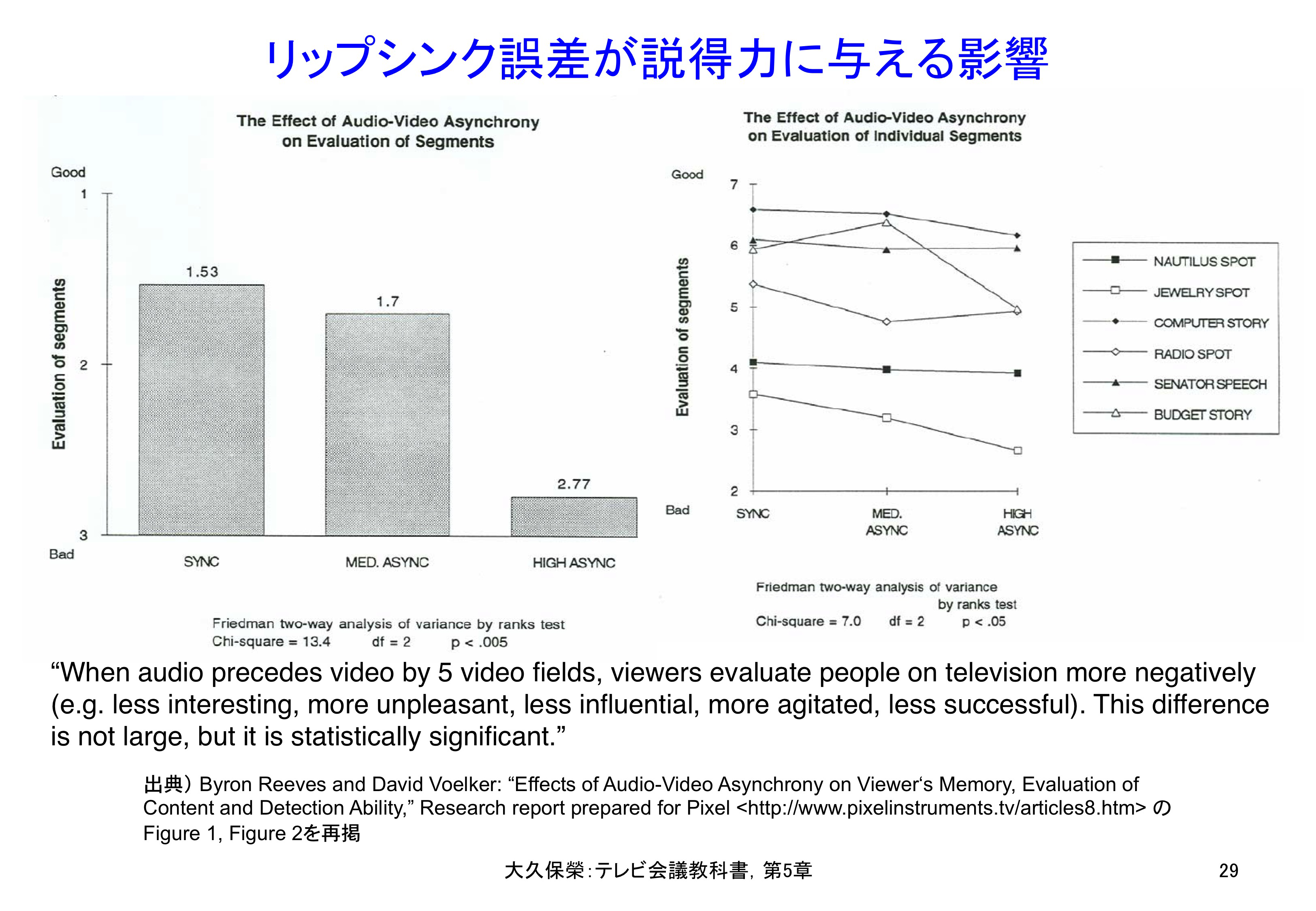
誤差なし(SYNC),2.5フィールド時間音声先行の場合(MED. ASYNC),5フィールド時間音声先行の場合(HIGH SYNC)の印象を尋ねた実験結果です.評価尺度は反対語対を7等分した評点です.ここでsegmentは評価に使ったビデオ番組のことで,6種類あります.なお,NAUTILUSはフィットネスクラブの名前です.
2) 映像がある場合の音像定位
映像がない場合,音はスピーカの置かれた場所から聞こえてきます.もっともステレオ再生装置の場合,モノラル音源であっても左右のスピーカに供給する音のレベルを調整することで,二つのスピーカの間で聞こえてくる音の位置を変えることができますが,その場合でも仮想的なスピーカ位置からしか音は聞こえてきません.
問題は,話している人の映像を見ているときにその声はどこから聞こえてくるように感じるかです.画面の口の位置からか,物理的なスピーカ位置からか,あるいはその中間からかです.
NHKで行われた音像定位実験結果とそのまとめを図5-30に示します[5-37].女性アナウンサーがニュースを読むバストショット映像を表示するディスプレイに対し,上記ステレオ再生装置によるレベル調整で仮想的なスピーカ位置を変えて,実験参加者に音が聞こえる方向を示して貰います.その測定結果が図5-30の右側のグラフです.横軸のスピーカ位置が画面に近い領域では画面に引き寄せられた方向から聞こえると感じられ,画面から十分離れるとスピーカ位置から聞こえるように感じられています.それを整理したのが図5-30左側です.10度区切りで3分割され,Aは音像定位が映像に引き込まれる領域,Cは音像が独立して定位される領域,Bは不安定領域となっています.
テレビ会議システムでは,スピーカ位置はディスプレイ中央である必要はありませんが,図5-30のA領域に入れることが推奨されます.
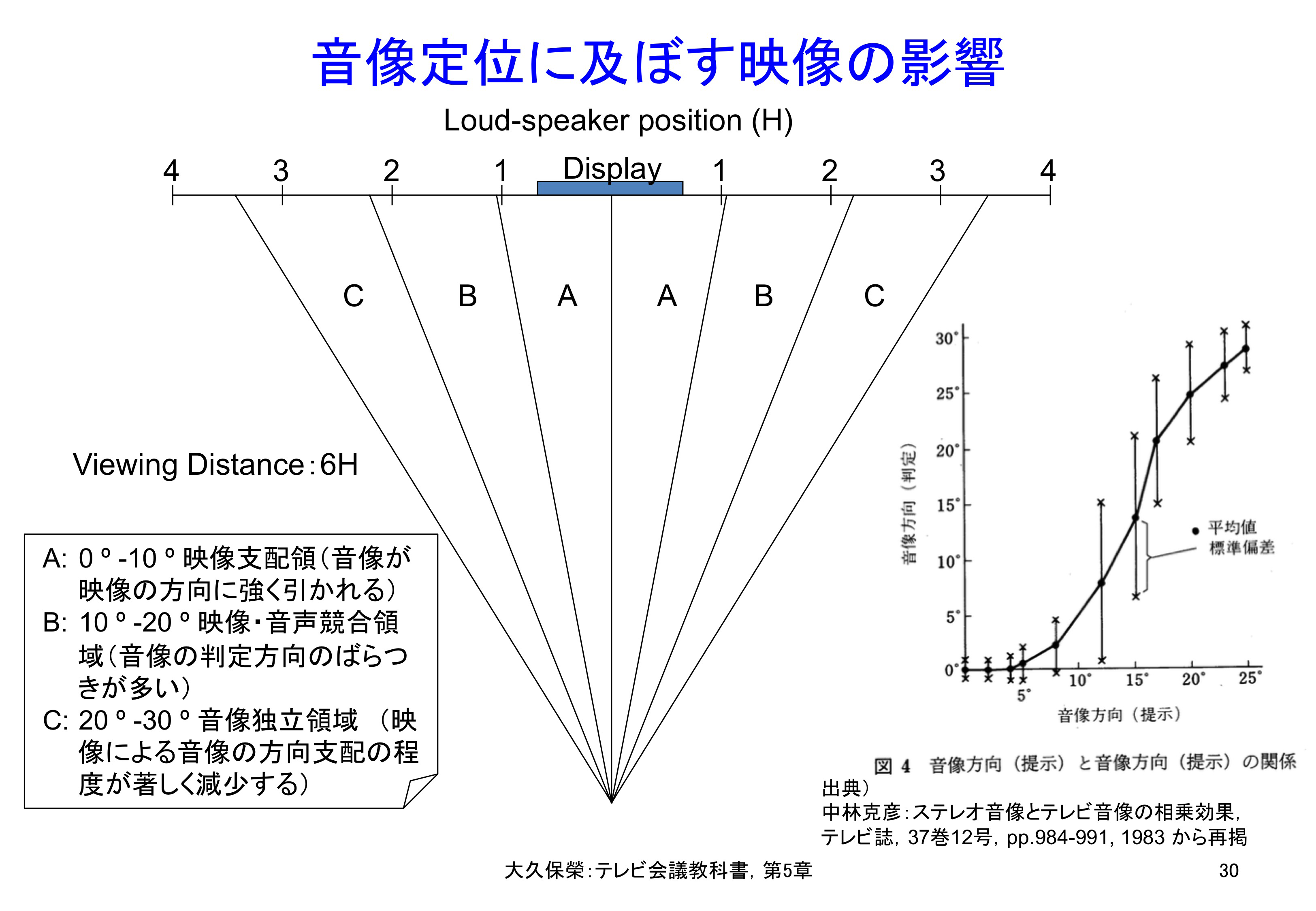
女性アナウンサーがニュース原稿を読む場面で,スピーカ設置位置を変えたとき,主観的にどの方向から音が聞こえてくるかを実験した結果です.スピーカ位置の単位Hは画面高を表しています.スピーカ位置が中心から左右10度の範囲に入っていれば,画面の位置から声が聞こえるように感じます.
3) ステレオ音声による音像定位
テレビ会議において,ステレオ音声により発言者の着席方向からその人の音声が聞こえるようにすると,どのような効果があるかが東工大で調べられています[5-38].実験の配置と結果を図5-31に示します.音像定位処理した場合とモノラル音声の場合を比べられるようにした実験環境で,実験者が片側の実験参加者に質問をし,その答えについてもう片側の実験参加者が何が答えられたか,誰が答えたかを調べています.質問に答える実験参加者を聞き取る実験参加者が知っている場合と未知の場合をパラメータにしています.実験結果は,音像定位処理を入れることにより,誰が何を答えたかについて,モノラルの場合より有意に識別率が高くなっています.
テレプレゼンス・システムの実装例では左,中央,右の音声チャネルを用意し,音像定位機能を提供していますし[5-39],要求条件を記述したITU-T F.734[5-29]でもこの機能を推奨しています.
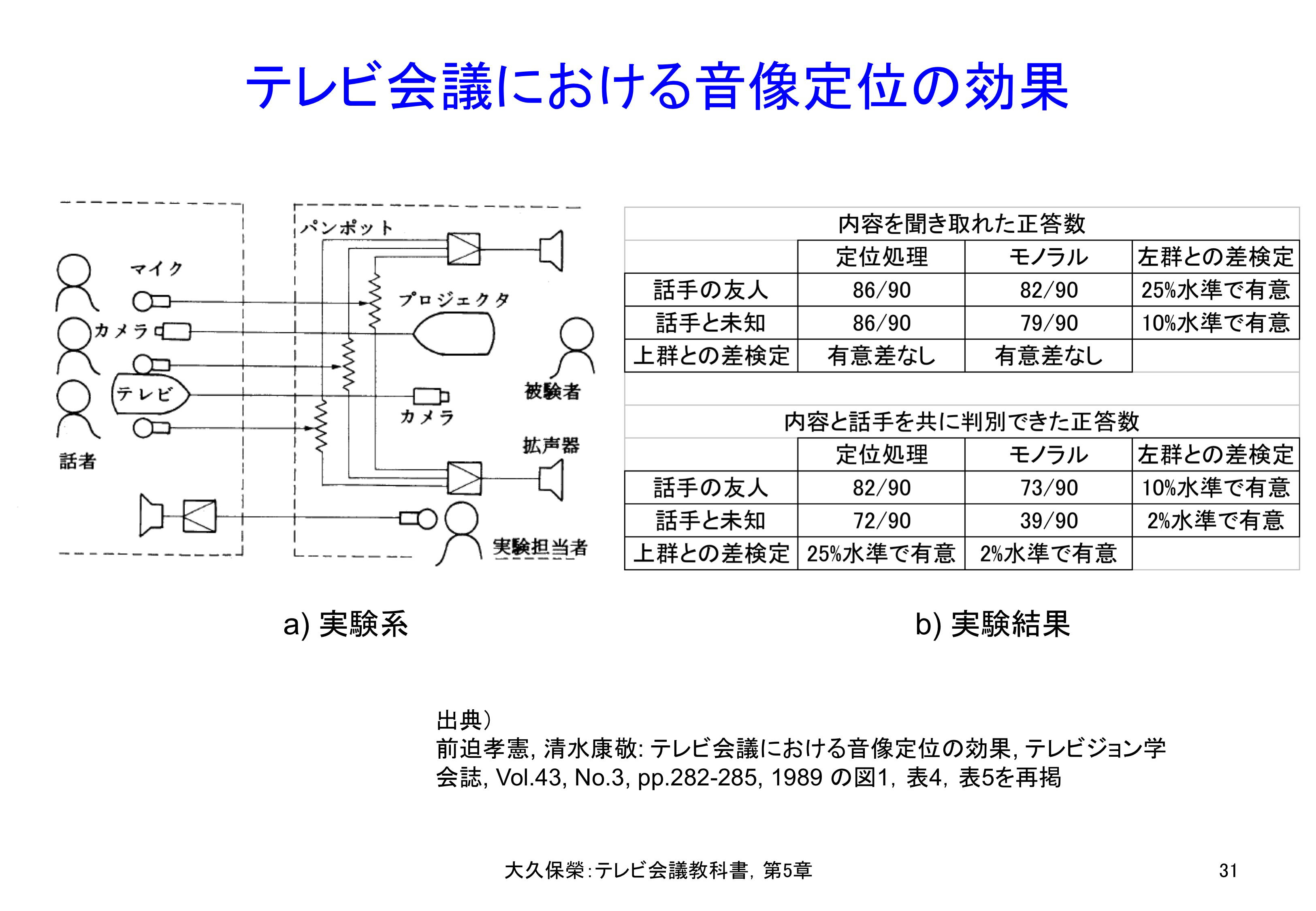
a)は実験系を示します.話し手の一人一人にマイクロホンがあり,その声は別々のチャネルで聞き手側に送られて,空間的な位置が再現できるように調整されます.実験担当者の質問に話し手が答える言葉と話し手が誰であるかを聞き手に識別して貰います.b)は実験結果を示します.ここで有意水準の値が小さいほど統計的有意度が増すことを表しています.音像定位処理により内容と話し手を共に識別する効果の大きくなることが示されています.